Como uso IA no meu workflow: três sistemas de agentes para contextos diferentes
TL;DR: Sou Builder e uso IA em praticamente tudo hoje: Claude Code como ambiente central, três arquiteturas distintas de agentes dependendo do contexto (conteúdo, código, backend), nano-banana-pro para imagens, veo3 para vídeos e um sistema de memória em markdown. Não é automação mágica. É um conjunto de ferramentas e fluxos que construí ao longo dos últimos meses, com muita tentativa e erro. Aqui está o que funciona e o que ainda não funciona.
Alguns meses atrás, o meu workflow com IA era basicamente: abrir o ChatGPT, digitar uma pergunta, copiar a resposta, ajustar manualmente. Repetir.
Hoje é diferente. Não dramaticamente diferente no sentido de "a IA faz tudo". Mas diferente no sentido de que construí sistemas onde a IA amplifica cada parte do meu trabalho, e não só a parte de "escrever texto".
Este post é um mapa do meu workflow atual: ferramentas, decisões de arquitetura e o que não funcionou. Sem embelezamento.
O que é o Claude Code e por que virou meu ambiente principal?
Claude Code é o ambiente de IA da Anthropic que opera diretamente no terminal, com acesso aos seus arquivos, projetos e ferramentas externas via MCP (Model Context Protocol). Diferente de um chatbot, ele age: lê pastas, escreve arquivos, roda comandos, chama APIs.
Testei o Cursor e o Windsurf antes. Ambos são bons, especialmente para quem fica dentro de um editor de código o dia inteiro. O Cursor tem autocomplete agressivo e UI agradável. O Windsurf tem a Cascade, que tenta raciocinar sobre o projeto de forma mais holística.
Mas para o meu caso, nenhum dos dois servia tão bem. Meu trabalho não é só código. É pesquisa, criação de conteúdo, análise de dados, comunicação. O Claude Code construiu este blog inteiro usando agentes em paralelo, com contextos isolados para cada tarefa. Quando vi isso funcionando, entendi que o paradigma que eu precisava era de um agente que pensa e executa, não de um autocomplete mais esperto.
Uso os dois. Claude Code para o trabalho pesado. Cursor quando estou no fluxo de código e quero autocomplete rápido.
Não tenho um sistema de agentes. Tenho três.
O erro que cometi no início foi tentar criar um sistema de agentes universal. Um orquestrador que servia para escrever posts e também para debugar código e também para revisar PRs. Não funciona.
O contexto que um agente de conteúdo precisa é completamente diferente do que um agente de desenvolvimento precisa. Depois de testar em vários projetos, convergi em três arquiteturas distintas, cada uma adaptada ao seu contexto:
- Orquestrador + Skills: para trabalho criativo e de conteúdo
- Maestro + Personas: para desenvolvimento de código
- Config-driven + Docs: para manutenção de backend e APIs
Os três rodam dentro do Claude Code. O que muda é a estrutura de como os agentes são organizados e como se especializam.
Arquétipo 1: Orquestrador + Skills (conteúdo e criação)
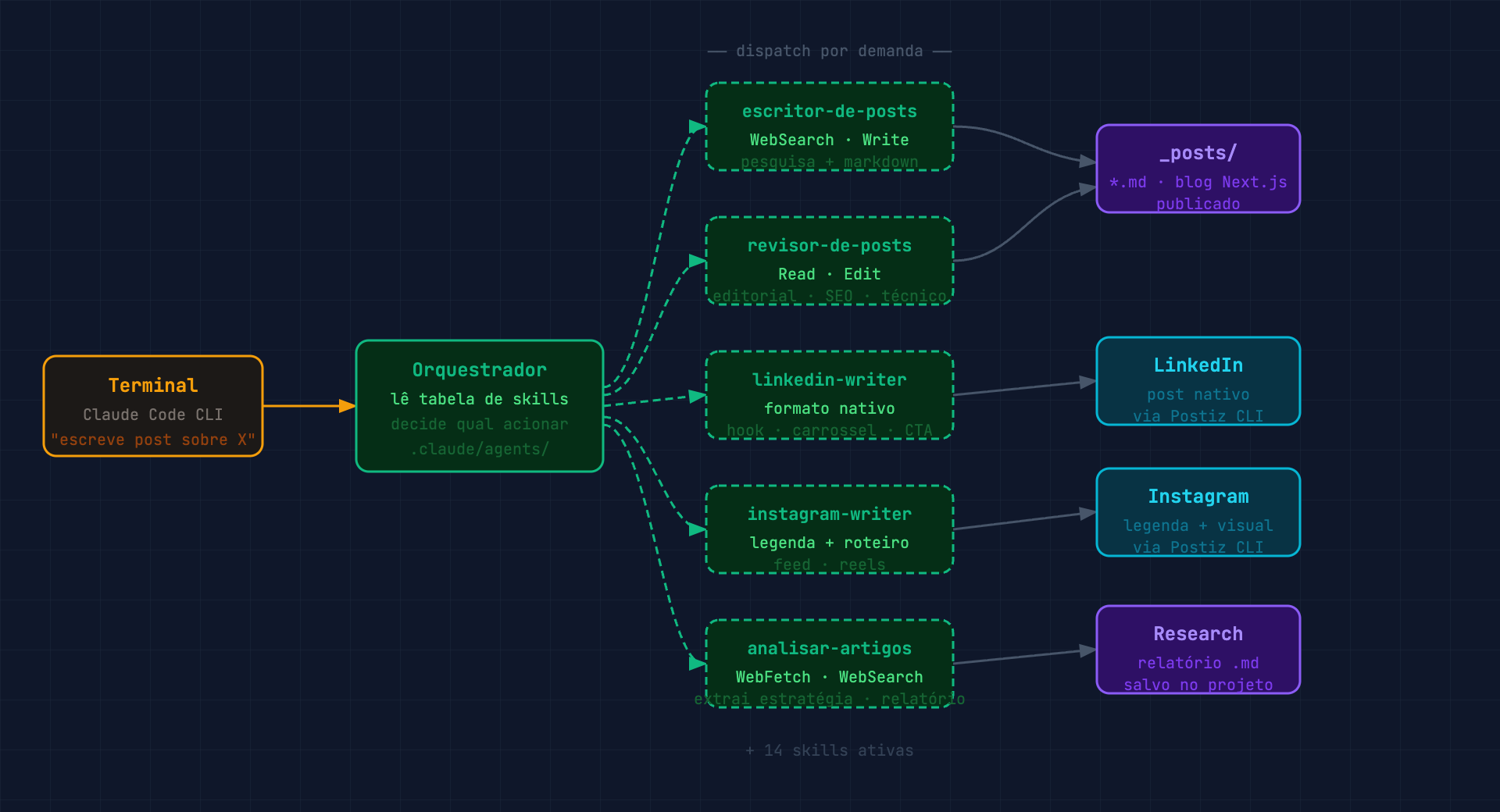
Para trabalho criativo, o sistema mais eficiente que encontrei é um orquestrador central com skills chamadas sob demanda.
O orquestrador é um agente genérico com acesso a uma tabela de skills disponíveis. Quando recebe um pedido, lê a tabela, decide qual skill acionar e passa o controle. As skills são arquivos markdown com instruções detalhadas: playbook completo de como fazer uma coisa específica muito bem.
A estrutura que roda este blog tem 19 skills ativas:
- escritor-de-posts: pesquisa na web, escreve, salva o markdown no lugar certo
- revisor-de-posts: confere nas três dimensões: editorial, SEO e técnico
- linkedin-writer: adapta o conteúdo para o formato nativo do LinkedIn
- instagram-writer: legendas e roteiros com as especificidades do Instagram
- youtube-writer: roteiros, títulos e descrições com hook e retenção
- analisar-artigos: lê URLs, extrai estratégia, salva relatório consolidado
- meta-ad-library: usa Chrome via MCP para espionar criativos na Biblioteca de Anúncios da Meta
O motivo de separar em skills é o contexto. Uma skill de 200 linhas de instruções específicas para escrever posts SEO-first é muito mais eficaz do que um agente genérico tentando fazer tudo. Cada skill só entra no contexto quando é chamada. O restante não existe para o agente.
Para criar um post, descrevo o tema para o orquestrador. Ele chama o escritor, que pesquisa na web, verifica o sitemap do blog para links internos, escreve o post em markdown e salva no lugar certo. Depois chama o revisor. Um post que levaria 4 horas de trabalho concentrado hoje leva cerca de 40 minutos. Meu tempo vai em revisar e ajustar, não em escrever do zero.
Quando usar esse arquétipo: trabalho criativo com formatos bem definidos, onde cada formato tem regras claras o suficiente para escrever um playbook.
Se quiser entender como estruturar esses agentes sem o contexto explodir, escrevi sobre isso em detalhes no post sobre como evitar que o contexto de agentes exploda.
Arquétipo 2: Maestro + Personas (desenvolvimento de código)
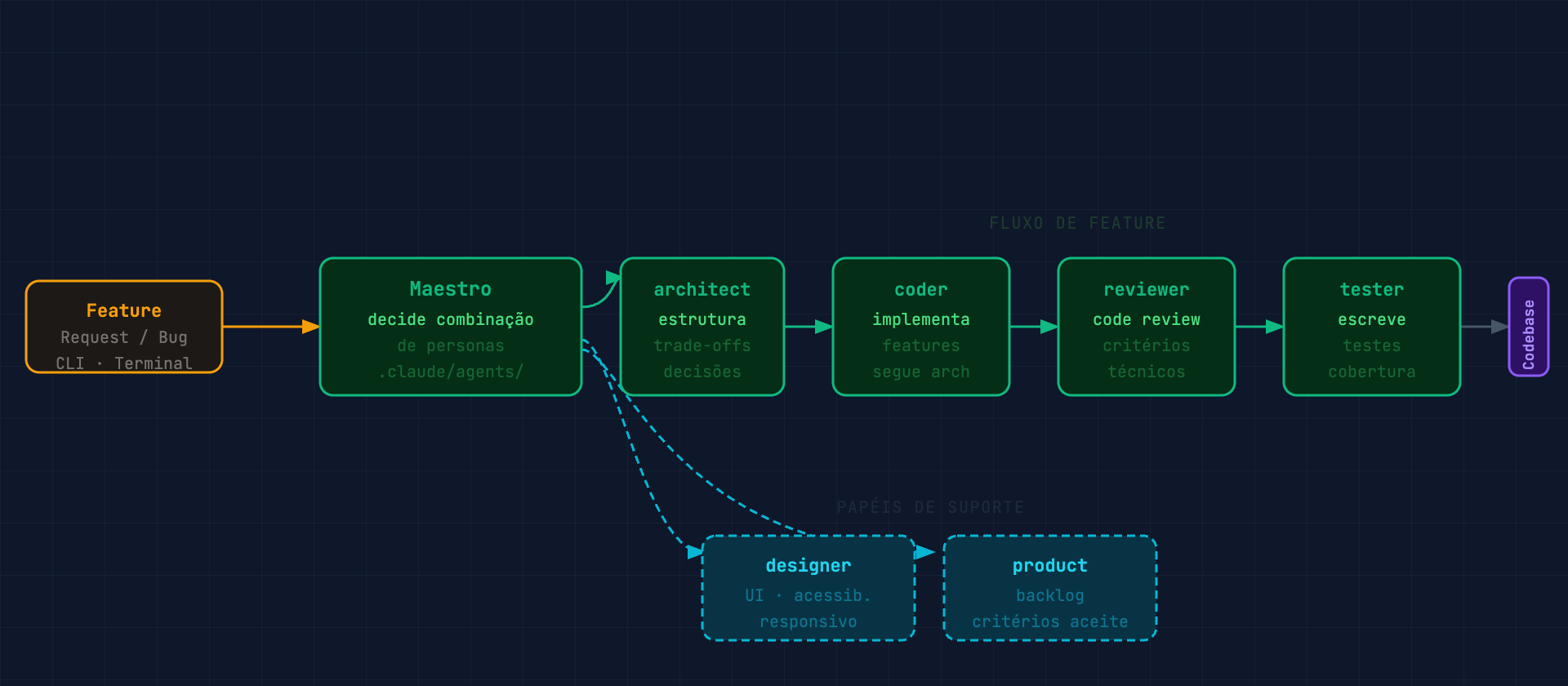
Para desenvolvimento de software, a estrutura mais eficiente que encontrei usa o padrão de um maestro que orquestra personas especializadas por disciplina.
As personas são agentes com identidade técnica específica:
- architect: define estrutura, decisões de arquitetura, trade-offs
- coder: implementa features, segue as decisões do architect
- reviewer: code review com critérios técnicos definidos
- tester: escreve e executa testes, reporta cobertura
- designer: componentes de UI, acessibilidade, responsividade
- product: backlog, priorização, critérios de aceite
O maestro recebe o pedido, decide qual combinação de personas acionar e coordena a execução. Para uma nova feature: architect (decisões de design) → coder (implementação) → reviewer (code review) → tester (testes). Para um bug crítico, vai direto para coder + tester sem passar pelo architect.
Uso essa estrutura nos projetos de frontend e em outros produtos que desenvolvo. O que diferencia das skills de conteúdo é que as personas têm mais autonomia entre si: o coder pode fazer perguntas ao architect antes de implementar, o reviewer pode pedir ao coder para ajustar antes de aprovar. É mais diálogo, menos pipeline sequencial.
Uma vantagem desse modelo é que diferentes personas podem rodar em modelos diferentes. Tarefas de raciocínio pesado (architect, reviewer) ficam em modelos mais capazes. Tarefas de execução direta (coder gerando boilerplate, tester escrevendo casos padronizados) ficam em modelos mais rápidos.
Quando usar esse arquétipo: projetos de software com múltiplas disciplinas onde as responsabilidades são bem separadas entre papéis.
Arquétipo 3: Config-driven + Docs (manutenção de backend)
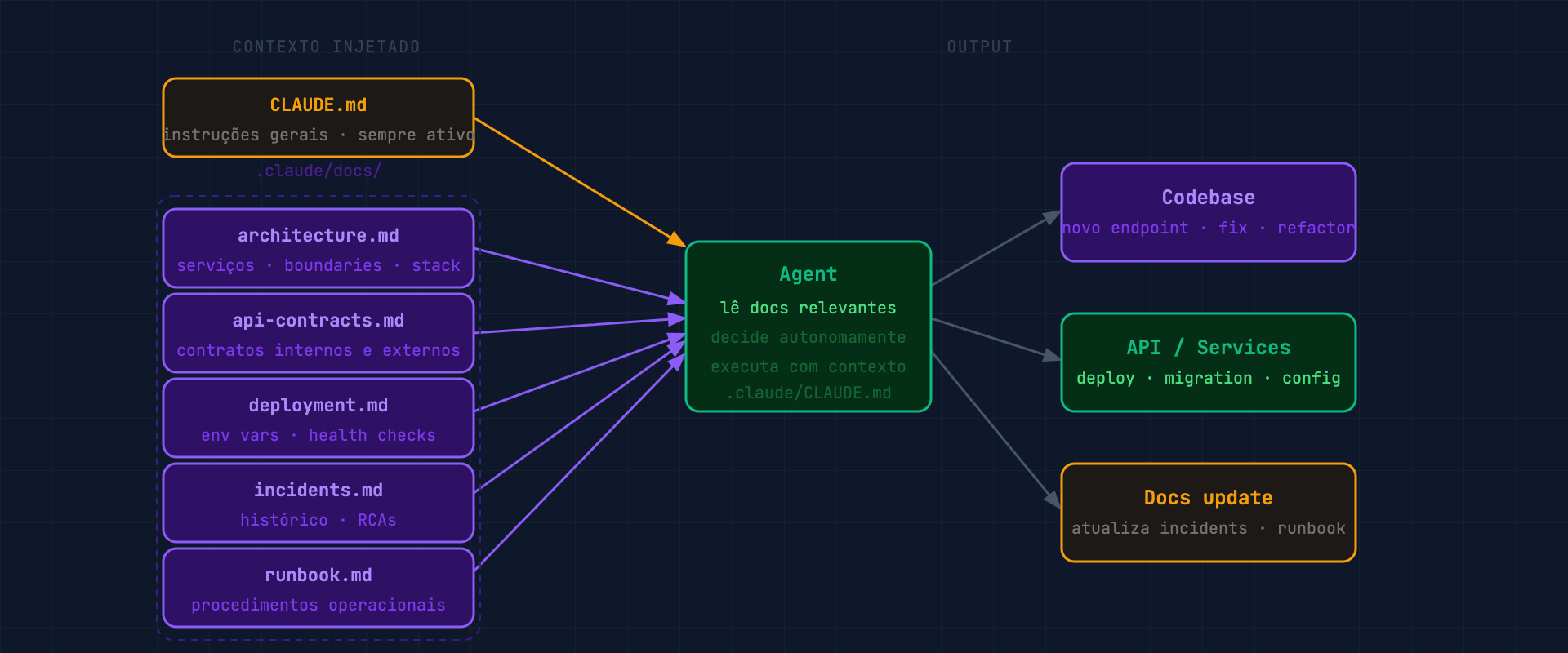
Para projetos de backend e APIs que já estão em produção, o overhead de um orquestrador explícito não vale o custo. O que funciona melhor é injetar contexto rico pelo sistema de documentação.
A estrutura é mais simples: um CLAUDE.md na raiz do projeto com instruções gerais, e uma pasta .claude/docs/ com documentação técnica que o agente lê quando precisa.
Nos projetos de backend que mantenho, o .claude/docs/ tem:
architecture.md: estrutura de serviços, responsabilidades, fronteirasapi-contracts.md: contratos de API internos e externosdeployment.md: como fazer deploy, variáveis de ambiente, health checksincidents.md: histórico de incidentes relevantes e como foram resolvidosrunbook.md: procedimentos operacionais padrão
Quando peço ao agente para adicionar um endpoint, ele lê a arquitetura antes de escrever código. Quando peço para depurar um problema de performance, ele consulta o histórico de incidentes. O agente não tem um playbook rígido, tem contexto suficiente para tomar decisões razoáveis.
A diferença em relação aos outros dois arquétipos é que aqui o agente age com mais autonomia por tarefa. Não há uma sequência de passos definida. O agente recebe o objetivo, consulta a documentação relevante e executa.
Quando usar esse arquétipo: sistemas em produção onde o principal valor do agente é entender o contexto existente antes de agir, não seguir um playbook de criação.
Os princípios que ficaram depois de testar tudo
Três arquétipos, dezenas de agentes, vários projetos. O que aprendi sobre como fazer isso funcionar:
Tamanho importa. Agentes com menos de 80 linhas de instrução performam melhor do que agentes com 300. Não porque o modelo não consegue processar, mas porque instruções longas criam ambiguidade. Quando há conflito entre duas instruções distantes no arquivo, o agente escolhe uma de forma imprevisível. Seja específico, seja curto.
A description é o mecanismo de seleção. Quando o orquestrador precisa decidir qual agente chamar, ele lê a description de cada um. Uma description vaga ("agente de conteúdo") resulta em seleção errada. Uma description precisa ("escreve posts de blog em português, SEO-first, com answer capsules e frontmatter em formato específico") resulta em seleção certa. É onde você investe mais atenção.
Progressive disclosure. O CLAUDE.md é sempre ativo: coloque lá apenas o que o agente precisa saber em toda tarefa. Skills e documentação são carregadas sob demanda. Não jogue tudo no CLAUDE.md só porque é conveniente. Contexto desnecessário polui o raciocínio.
Red lines funcionam. Definir o que o agente nunca deve fazer é tão importante quanto definir o que ele deve fazer. "Nunca commite sem rodar os testes." "Nunca modifique arquivos de configuração de produção." "Nunca publique conteúdo sem verificar os links internos." Red lines são salvaguardas que funcionam porque o modelo as respeita quando estão explícitas.
Como os agentes fazem pesquisa de mercado no meu workflow?
No Arquétipo 1, agentes de pesquisa recebem uma URL ou tema, varrem o conteúdo via WebSearch e WebFetch, extraem estratégias e dados relevantes, e salvam um relatório consolidado no projeto. O que antes levava 2 horas de leitura manual vira 20 minutos de revisão de síntese gerada pelo agente.
Tenho uma skill chamada analisar-artigos que recebe um artigo ou um conjunto de URLs, lê o conteúdo, extrai estratégias, dados e aprendizados relevantes e salva um arquivo consolidado no projeto. Outra skill, meta-ad-library, usa o Chrome via MCP para espionar criativos na Biblioteca de Anúncios da Meta e extrair padrões de hooks, copy e visuais que estão funcionando.
Para pesquisa de concorrentes, tenho uma skill de análise de canal do YouTube que analisa o canal inteiro, identifica os vídeos de maior performance e produz um guia estratégico.
O que isso resolve na prática: antes, pesquisa de mercado eram 2 horas de leitura e anotações manuais. Hoje, o agente faz a varredura, eu reviso o relatório em 20 minutos e tomo as decisões com mais informação.
Como fazer o agente lembrar quem você é entre sessões?
A solução mais simples é um arquivo de memória em markdown. Um MEMORY.md funciona como índice do que o agente precisa saber: preferências, projetos ativos, ferramentas, decisões passadas. No início de cada sessão, o agente carrega o arquivo e retoma o contexto. Sem banco de dados, sem embedding, sem infraestrutura extra.
O problema que qualquer um enfrenta com LLMs é exatamente este. Cada conversa começa do zero.
O MEMORY.md tem seções para preferências de escrita, projetos ativos, ferramentas que uso e decisões que tomei. Quando algo novo é relevante manter, o agente atualiza o arquivo.
Documentei o sistema completo, com exemplos de estrutura e quando ele falha, no post sobre memory em agentes Claude Code.
Parece simples porque é simples. Não precisa de banco de dados, não precisa de embedding. Um sistema de arquivos de texto bem organizado resolve 80% do problema de memória para uso individual.
A limitação real é que o sistema precisa ser mantido. Se o MEMORY.md fica desatualizado, a qualidade das interações cai. Isso é overhead que não existia antes. Não é neutro.
Imagens e vídeos: nano-banana-pro e veo3
Para imagens, uso o nano-banana-pro, que é o Gemini 3 Pro Image da Google. Na prática: descrevo o que preciso, o agente gera via API, o arquivo fica salvo no projeto. Uso para slides de carrossel, thumbnails e imagens de feed do Instagram.
A limitação honesta: consistência de personagem ainda é fraca. Se você precisar do mesmo personagem em múltiplos frames, vai precisar de trabalho manual. Para assets isolados, funciona muito bem.
Para vídeos, uso o veo3, que é o Veo 3.1 da Google. O diferencial do Veo 3 em relação à geração anterior é o áudio nativo: o modelo gera o clipe já com efeitos sonoros e áudio ambiente sincronizados.
Uso para B-roll de vídeos do YouTube e clipes para reels. A qualidade é boa para o propósito. Não substituiu câmera real, mas resolveu situações onde eu precisaria de stock footage pago ou produção que não tinha.
Publicação: Postiz CLI para 28 plataformas
A parte final do pipeline é publicação. Uso o Postiz, uma CLI que publica em 28+ plataformas sociais. Com uma configuração inicial, consigo agendar posts para LinkedIn, Instagram, Threads, YouTube e mais a partir do terminal.
O fluxo completo fica assim: agente escreve o post do blog, publica no Next.js, agente adapta para LinkedIn, agente adapta para Instagram (com legenda e sugestão de visual), Postiz agenda tudo com um comando.
O que seria 3-4 horas de trabalho vira 40-60 minutos, com a maior parte indo para revisão de conteúdo.
O que não funciona bem ainda
Seria desonesto deixar só o lado bom.
Consistência visual é o maior buraco. Cada imagem gerada pelo nano-banana-pro é independente. Construir identidade visual consistente com IA ainda requer muito prompt engineering e revisão manual.
Alucinação em dados acontece. Quando peço para o agente pesquisar dados de mercado, às vezes ele inventa números plausíveis. Aprendi a sempre pedir as fontes e verificar antes de publicar.
Latência em tarefas longas. Quando o orquestrador encadeia 3-4 agentes em sequência, o processo pode levar 15-20 minutos. Não é problema para trabalho assíncrono, mas para iteração rápida incomoda.
Custo. O stack hoje me custa em torno de USD 40-60 por mês entre Claude Code (plano Max, $100-200/mês com custo fixo e limites de uso maiores), APIs do Google e Postiz. As APIs do Google (Gemini, Veo) têm custo variável por geração. Para quem está começando, Claude Code no Pro ($20/mês) + uso básico de APIs fica perto de $25-30/mês. Documentei os números reais de token, tempo e falha no post sobre custo real de agentes IA em produção.
Como começar sem construir tudo de uma vez?
Não precisa montar nenhum dos três sistemas no primeiro dia. Comece por uma tarefa que você já faz manualmente, passe para o Claude Code, veja o resultado e itere. A complexidade vem depois, quando você já entende o que o agente faz bem e onde ele precisa de supervisão.
A ordem que faria se começasse hoje:
- Escolha um contexto: conteúdo, código ou backend
- Comece com Claude Code no terminal para uma tarefa simples nesse contexto
- Depois pense em uma skill ou persona: um agente que faz uma coisa bem feita
- Só então pense em orquestração e múltiplos agentes
Escolha o arquétipo pelo tipo de trabalho: se é criativo com formatos definidos, vai para Orquestrador + Skills. Se é desenvolvimento com múltiplas disciplinas, vai para Maestro + Personas. Se é manutenção de sistema existente, vai para Config-driven + Docs.
Quando documentei como o Claude Code trabalhou durante a noite para entregar uma feature, o que ficou claro foi que o trabalho real é definir bem o contexto antes de delegar. O agente executa bem quando a especificação é boa. Mal quando não é.
O sistema vai continuar evoluindo
Não é um stack fixo. Estou adicionando skills novas, ajustando prompts, testando ferramentas. O que está documentado aqui é o estado de abril de 2026.
Nos próximos meses, quero integrar mais análise de dados de produto direto no workflow. Agentes que leem dashboards, identificam anomalias e geram rascunhos de hipóteses para investigar. Ainda está no nível de experimento.
Se quiser acompanhar a evolução do sistema, a newsletter é o melhor lugar. Mando updates sempre que algo muda de forma relevante, com exemplos concretos e o que aprendi no caminho. Sem spam, sem promessa de curso.
Assine abaixo para receber os próximos updates.
Perguntas Frequentes
Por que Claude Code em vez de Cursor ou Windsurf?
Para o meu caso de uso, que combina código, escrita e automação de fluxos, o Claude Code funciona melhor porque opera de forma agêntica no terminal, com acesso a arquivos e ferramentas externas. Cursor e Windsurf são mais fortes para quem fica majoritariamente dentro de um editor de código com autocomplete rápido. Os dois paradigmas são complementares, não excludentes.
Qual arquétipo de agente é melhor para começar?
Depende do que você faz. Para Builders que produzem conteúdo (posts, LinkedIn, vídeos), o Orquestrador + Skills é o de entrada mais fácil: você define um formato, escreve o playbook e já tem resultado. Para quem desenvolve software em equipe pequena, o Maestro + Personas escala melhor. Para quem mantém sistemas em produção, o Config-driven é o menos arriscado.
Quanto tempo leva para construir um sistema de agentes?
O sistema básico (orquestrador + 2 ou 3 skills, ou maestro + 3 personas) pode estar funcionando em um fim de semana se você já tem familiaridade com Claude Code. O que leva mais tempo é iterar nos prompts até a qualidade ficar consistente. Planeje de 4 a 8 semanas para ter algo que funciona com pouca revisão manual.
O sistema de memória em markdown escala?
Para uso individual, sim. Para equipes, começa a ter fricção a partir de 3 ou 4 pessoas editando os mesmos arquivos. Nesse caso, vale olhar soluções com banco de dados e embedding. Para solo, markdown funciona muito bem e tem a vantagem de ser simples de manter e versionar com git.
Como garantir que o agente não publica conteúdo com erro ou dado falso?
O revisor de posts é a camada de verificação, mas não é infalível. Tenho como regra verificar manualmente qualquer dado numérico ou afirmação factual antes de publicar. O agente é bom em estrutura, tom e SEO. A curadoria de fatos ainda é responsabilidade minha. Isso não vai mudar tão cedo.
Qual o custo mensal do stack completo?
Em torno de USD 40-60 por mês baseado no meu uso. O Claude Code tem planos fixos: Pro ($20/mês) e Max ($100-200/mês). Uso o plano Max, que cobre o Claude Code com limites de uso maiores e custo previsível, sem pagar por token. As APIs do Google (Gemini, Veo) têm custo variável por geração, e o Postiz tem plano pago para volume maior. Para quem está começando, Claude Code no Pro + uso básico de APIs fica perto de $25-30/mês.
Como organizar as skills para o orquestrador escolher certo?
O campo description da skill é o mecanismo de seleção, não o nome. Escreva descrições em forma de gatilho: "Use quando o usuário pedir para escrever ou revisar um post". O orquestrador lê as descrições disponíveis e decide qual chamar. Se duas skills parecem resolver o mesmo problema, a descrição mal escrita vai fazer o orquestrador escolher errado. Uma skill bem descrita em 20 palavras supera uma skill com 200 linhas de instrução mal rotulada.